相信每个用go写的项目都会搞一个go的协程池包,不论是自己写的还是借鉴开源代码。和其他语言编程中经常提到的线程池一样,协程池同样是通过协程复用、限制并发协程数量达到减轻频繁创建协程的开销和并发协程过多带来的系统消耗。
然而在大家热烈地讨论各种协程池的实现及优劣时,完全没有顾及go语言开发团队的感受,堂堂语言缔造者,难道就想不到内置一个goroutine池吗?(自问自答,当然想到了,要不然写这篇文章岂不成了标题党)。
go源码src文件夹下的子文件夹有46个,总文件数多达6611个。从这浩如烟海的代码中找到go内置goroutine池需要一些小技巧。
寻找源码入口
留给我们唯一的线索就是go关键字,go关键字创建并启动一个goroutine,如果我们找到源码中创建goroutine的位置,跟踪下去即可找到goroutine池使用的地方。
我们在main方法中启动了一个goroutine:
1
2
3
4
5
6
|
package main
func main() {
go func() {
}()
}
|
go是一个关键字,和func、var、make等关键字一样,在编译时它们会被替换为相应的其他方法,以上代码的汇编代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
go build
go tool objdump -s main.main main
TEXT main.main(SB) XXXX/main.go
main.go:3 0x1054be0 493b6610 CMPQ 0x10(R14), SP
main.go:3 0x1054be4 7629 JBE 0x1054c0f
main.go:3 0x1054be6 4883ec18 SUBQ $0x18, SP
main.go:3 0x1054bea 48896c2410 MOVQ BP, 0x10(SP)
main.go:3 0x1054bef 488d6c2410 LEAQ 0x10(SP), BP
main.go:4 0x1054bf4 31c0 XORL AX, AX
main.go:4 0x1054bf6 488d1d6b0b0100 LEAQ go.func.*+316(SB), BX
main.go:4 0x1054bfd 0f1f00 NOPL 0(AX)
main.go:4 0x1054c00 e8bb0cfeff CALL runtime.newproc(SB)
main.go:7 0x1054c05 488b6c2410 MOVQ 0x10(SP), BP
main.go:7 0x1054c0a 4883c418 ADDQ $0x18, SP
main.go:7 0x1054c0e c3 RET
main.go:3 0x1054c0f e88cd0ffff CALL runtime.morestack_noctxt.abi0(SB)
main.go:3 0x1054c14 ebca JMP main.main(SB)
|
不卖关子了,明眼人一看,就能猜到CALL runtime.newproc(SB)就是关键(其他指令都是栈操作和跳转),runtime是源码中的runtime包,那么我们在runtime包中搜索func newproc即可,newproc方法代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, argp, siz, gp, pc)
_p_ := getg().m.p.ptr()
runqput(_p_, newg, true)
if mainStarted {
wakep()
}
})
}
|
重点关注newproc1方法,它返回了newg,newg是指向新创建的g的指针,runqput(_p_, newg, true)将新创建的g(goroutine对象)放入了p的运行队列中(p代表processor,g代表goroutine,go的GMP模型),我们继续深入newproc1中,查看g是如何创建的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g {
...
_p_ := _g_.m.p.ptr()
newg := gfget(_p_)
if newg == nil {
newg = malg(_StackMin)
...
}
...
return newg
}
|
与goroutine池关系不大的代码已省略
第二行通过gfget方法获取一个g,如果没有获取到则调用malg创建一个g。可见gfget方法就是goroutine池的获取g的方法。我们搜索func gfget,定位到src/runtime/proc.go的4468行(不同版本代码行数不一定一样),可以看到三个相关方法:gfput,gfget,gfpurge。到这里我们基本已经确定了goroutine池代码的位置,下面简单介绍一下go内置goroutine池。
goroutine池
goroutine池的数据结构如下图:
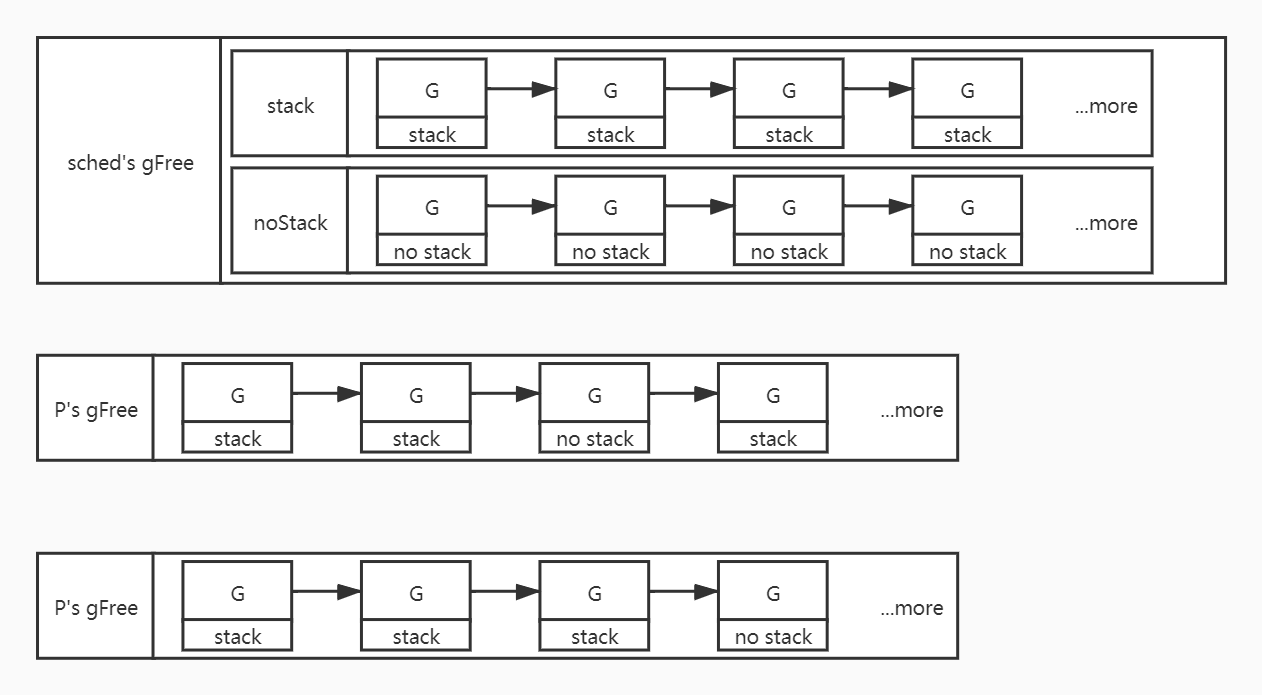
每个p中都有一个本地的goroutine池,即p中的gFree链表对象,存储着可用的goroutine。
sched中包含一个全局的goroutine池,即sched中的gFree对象,sched中gFree对象中又有两个子对象:stack和noStack对象,分别表示包含栈的goroutine链表、不包含栈的goroutine链表。
gfput
goroutine退出时调用goexit0,goexit0方法调用gfput将此goroutine放入到p的gFree链表中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
// Put on gfree list.
// If local list is too long, transfer a batch to the global list.
func gfput(_p_ *p, gp *g) {
if readgstatus(gp) != _Gdead {
throw("gfput: bad status (not Gdead)")
}
stksize := gp.stack.hi - gp.stack.lo
if stksize != _FixedStack {
// non-standard stack size - free it.
stackfree(gp.stack)
gp.stack.lo = 0
gp.stack.hi = 0
gp.stackguard0 = 0
}
_p_.gFree.push(gp)
_p_.gFree.n++
if _p_.gFree.n >= 64 {
var (
inc int32
stackQ gQueue
noStackQ gQueue
)
for _p_.gFree.n >= 32 {
gp = _p_.gFree.pop()
_p_.gFree.n--
if gp.stack.lo == 0 {
noStackQ.push(gp)
} else {
stackQ.push(gp)
}
inc++
}
lock(&sched.gFree.lock)
sched.gFree.noStack.pushAll(noStackQ)
sched.gFree.stack.pushAll(stackQ)
sched.gFree.n += inc
unlock(&sched.gFree.lock)
}
}
|
- gfput首先判断g的栈大小是否是标准大小(目前是2k),如果不是则释放g中的栈
- 将g放入到p本地的gFree链表中
- 如果p本地的gFree中的g数量>=64,则将p本地的g转移到sched中的gFree中,直到p本地的数量小于32
gfget
启动一个新goroutine时调用newproc1方法,newproc1方法调用gfget查询是否有可用的g,如果有则返回,没有则创建一个
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
// Get from gfree list.
// If local list is empty, grab a batch from global list.
func gfget(_p_ *p) *g {
retry:
if _p_.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) {
lock(&sched.gFree.lock)
// Move a batch of free Gs to the P.
for _p_.gFree.n < 32 {
// Prefer Gs with stacks.
gp := sched.gFree.stack.pop()
if gp == nil {
gp = sched.gFree.noStack.pop()
if gp == nil {
break
}
}
sched.gFree.n--
_p_.gFree.push(gp)
_p_.gFree.n++
}
unlock(&sched.gFree.lock)
goto retry
}
gp := _p_.gFree.pop()
if gp == nil {
return nil
}
_p_.gFree.n--
if gp.stack.lo == 0 {
// Stack was deallocated in gfput. Allocate a new one.
systemstack(func() {
gp.stack = stackalloc(_FixedStack)
})
gp.stackguard0 = gp.stack.lo + _StackGuard
} else {
if raceenabled {
racemalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
if msanenabled {
msanmalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
}
return gp
}
|
- gfget首先判断p本地的gFree链表是否为空,如果是空,则从sched的链表中转移最多31个g到p本地
- 从p本地的gFree链表中pop一个g
- 判断获取到的g的栈是否为空,如果是则为g分配一个标准大小的栈(2k)
gfpurge
gfpurge方法在p销毁时调用,gfpurge将p的gFree链表中的g转移到sched中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// Purge all cached G's from gfree list to the global list.
func gfpurge(_p_ *p) {
var (
inc int32
stackQ gQueue
noStackQ gQueue
)
for !_p_.gFree.empty() {
gp := _p_.gFree.pop()
_p_.gFree.n--
if gp.stack.lo == 0 {
noStackQ.push(gp)
} else {
stackQ.push(gp)
}
inc++
}
lock(&sched.gFree.lock)
sched.gFree.noStack.pushAll(noStackQ)
sched.gFree.stack.pushAll(stackQ)
sched.gFree.n += inc
unlock(&sched.gFree.lock)
}
|
gc
由于sched中的全局gFree链表中的g是没有数量限制的,为解决内存占用不断增长,在进行垃圾回收时,会对sched中带有栈的g进行栈释放。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// markrootFreeGStacks frees stacks of dead Gs.
//
// This does not free stacks of dead Gs cached on Ps, but having a few
// cached stacks around isn't a problem.
func markrootFreeGStacks() {
// Take list of dead Gs with stacks.
lock(&sched.gFree.lock)
list := sched.gFree.stack
sched.gFree.stack = gList{}
unlock(&sched.gFree.lock)
if list.empty() {
return
}
// Free stacks.
q := gQueue{list.head, list.head}
for gp := list.head.ptr(); gp != nil; gp = gp.schedlink.ptr() {
stackfree(gp.stack)
gp.stack.lo = 0
gp.stack.hi = 0
// Manipulate the queue directly since the Gs are
// already all linked the right way.
q.tail.set(gp)
}
// Put Gs back on the free list.
lock(&sched.gFree.lock)
sched.gFree.noStack.pushAll(q)
unlock(&sched.gFree.lock)
}
|
