简介
sync.Pool是go官方提供的多线程安全的对象缓存池。目的是达到内存复用,减少内存分配及gc带来的消耗。
官方fmt包就使用了sync.Pool,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
func Sprintf(format string, a ...interface{}) string {
p := newPrinter()
p.doPrintf(format, a)
s := string(p.buf)
p.free()
return s
}
var ppFree = sync.Pool{
New: func() interface{} { return new(pp) },
}
// newPrinter allocates a new pp struct or grabs a cached one.
func newPrinter() *pp {
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
// free saves used pp structs in ppFree; avoids an allocation per invocation.
func (p *pp) free() {
if cap(p.buf) > 64<<10 {
return
}
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}
|
ppFree缓存了使用过的pp对象,Get方法取出一个缓存的对象,Put归还一个对象。
下面我们来看一下源码,看看go官方是如何实现一个高性能的缓存池的。
数据结构
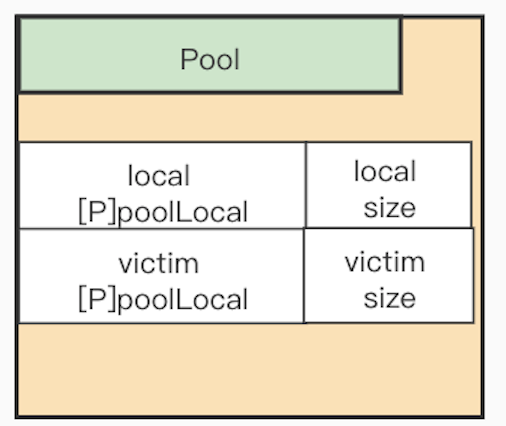
首先我们看一下Pool的数据结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() interface{}
}
|
Pool中主要的数据是local(victim后面介绍),如注释:local实际上是一个大小为P总数的数组地址,类型为[P]poolLocal,(P即GPM模型中的P,Processor),也就是每个P对应一个poolLocal。
我们知道GPM模型中,每个P对应一个M(即系统线程)。sync.Pool中为每个P设置一个pool,也就是每个线程使用自己的本地pool。解决了多线程共享数据需要进行加锁,带来的性能消耗。
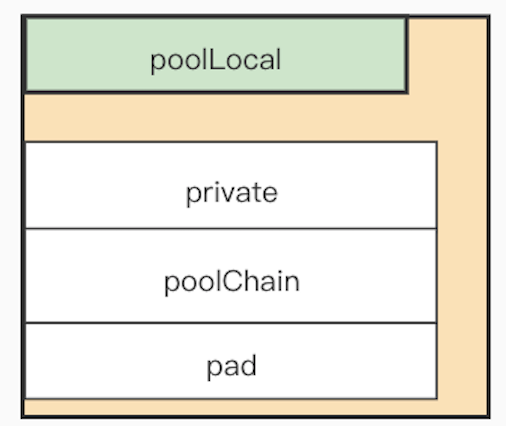
poolLocal
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// Local per-P Pool appendix.
type poolLocalInternal struct {
private interface{} // Can be used only by the respective P.
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
|
sync.Pool中进行缓存的Get和Put的一个快捷路径是检查private属性,Get时如果private不为空,则直接返回private中的数据并将private置空,Put时如果private为空,则直接将数据设置到private中。由于private只会被相同的P使用,所以不需要加锁也不需要使用原子操作。
当无法使用private时,才到shared中进行读写。shared是一个链表,如下:
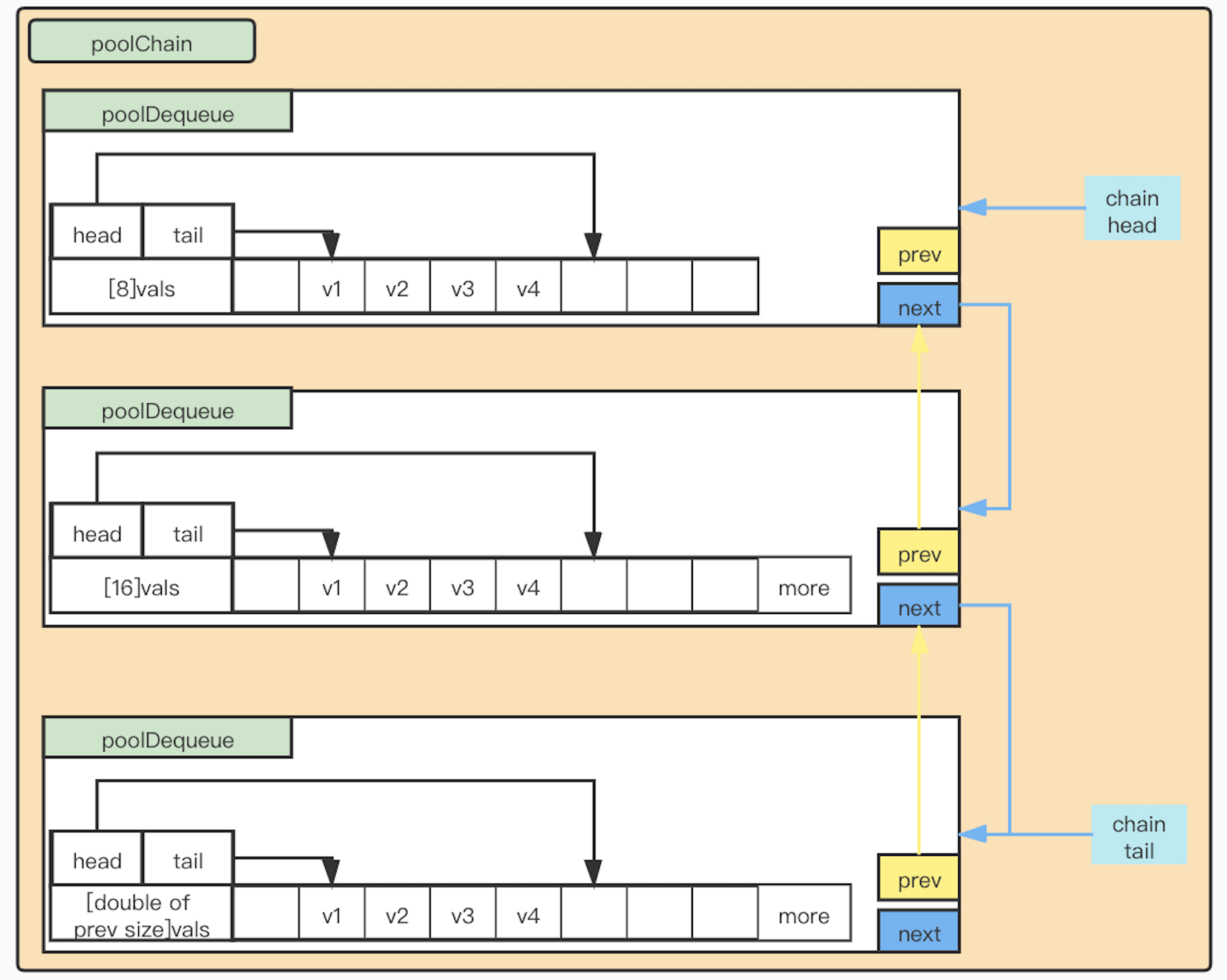
poolChain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type poolChain struct {
head *poolChainElt
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
next, prev *poolChainElt
}
type poolDequeue struct {
headTail uint64
vals []eface
}
|
poolChain是poolDequeue的双向链表,poolDequeue的vals是一个固定大小的数组,保存了缓存的数据。headTail的高32位指向vals中下一个可以Put数据的下标,低32位指向vals最早一个可取数据的下标。
poolChain中每一个poolDequeue的vals的大小是它前一个poolDequeue的vals大小的两倍。
当一个poolDequeue中的vals存满后,则新建一个两倍大小vals的poolDequeue。这种数组加链表的方式,一方面利用了数组这种顺序内存结构cpu缓存友好的优点,另一方面使用链表解决了数组扩容需要进行已有数据拷贝的弊端。
victim
victim和local变量有相同的数据结构。为了避免一次gc将缓存的数据都回收掉的问题。当进行gc时,会使用victim保存local中的数据,local设置为空,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
var (
allPools []*Pool
oldPools []*Pool
)
func poolCleanup() {
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// The pools with non-empty primary caches now have non-empty
// victim caches and no pools have primary caches.
oldPools, allPools = allPools, nil
}
|
poolCleanup在gc时调用。在sync.Pool的Get方法中,如果在local中获取不到时,则会到victim中进行获取。
总结
- 每个P一个pool,解决多线程共享数据需要加锁问题
- 设置private快速路径
- 固定大小数组加链表,解决扩容问题
- 使用二级缓存victim,解决一次gc令大面积缓存数据失效的问题
