最接地气的Go服务优化指南

Contents
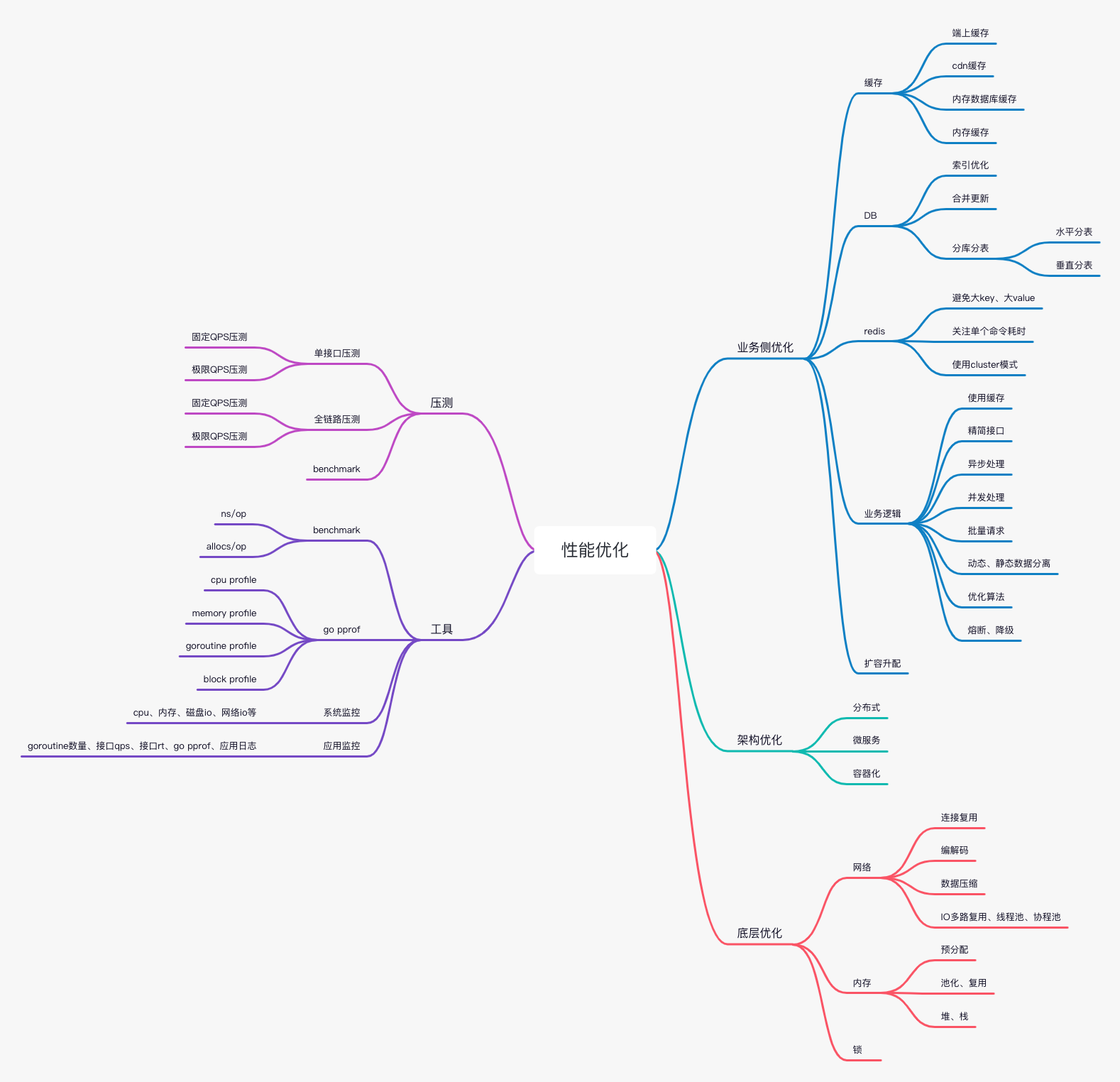
一、压测
1. 单接口压测
固定QPS压测
用于排查新功能对接口的影响
极限QPS压测
用于摸排接口最大承载QPS
2. 全链路压测
3. benchmark
用于代码层面方法的压测,可观察不同实现版本的方法的性能及内存使用
二、工具
1. benchmark(同上)
2. go pprof
- cpu profile,用于排查cpu占用较高的代码逻辑
- memory profile,用于排查内存占用较高的代码逻辑
- goroutine profile,用于排查goroutine占用较高的代码逻辑(即goroutine都在执行哪些逻辑)
- block profile,用于排查阻塞运行的代码逻辑,例如大锁(mutex锁定了一个运行时间较长的逻辑,且有很多其他goroutine在等待这个锁)
3. 系统监控
-
cpu
以固定速率增加压测qps,若cpu占用增长慢,接口延迟增长很快,可观察profile中的goroutine profile 和block profile,查看阻塞了运行的代码逻辑;若cpu占用增长快,可观察profile中的cpu profile,查看占用 cpu高的代码逻辑。
-
memory
内存占用高,不止影响内存使用,还会影响gc,使得gc时间增加
go进程中的内存占用除了运行时变量内存占用,还有goroutine内存占用。goroutine内存占用可以使用goroutine池限制并发goroutine数量,变量内存占用可观察memory profile,查看内存占用高的代码逻辑并进行优化
-
磁盘io
应用中与磁盘io性能相关的一般只有打印日志,可增加一个日志buffer,避免对磁盘的频繁写入。也可以开启日志采样。
-
网络io
系统网络指标一般只有总的流量,qps的增加必然伴随流量上升。如果压测qps增加,cpu不高,一般可以检查依赖的下游其他服务(也包括db和redis)接口rt是否上升。
针对io密集的服务,可以通过并发执行io请求,和使用批量io接口减少网络rtt带来的接口延迟。
4. 应用监控
-
goroutine数量
goroutine虽然已经足够轻量,但是并发goroutine太多,goroutine创建占用cpu、内存占用、调度带来的消耗都会体现出来。必要时可以使用goroutine池来限制最大并发数。
-
接口qps、rt
接口qps和rt是服务性能的基础指标,可针对重要接口的qps和rt进行报警监控。
-
go pprof
go pprof是go程序性能分析的重要工具
-
应用日志
应用日志也是服务监控的重要手段,合理的日志分级和报警策略可以帮助我们更早得发现性能问题。
三、业务侧优化
1. 缓存
-
端上缓存
将数据缓存到客户端或者浏览器
例如一些常用但不常变动的配置性数据端上可以在启动app时请求一次缓存到本地;针对一些高用户参与度的活动,可以将一些数据预埋到端上。
-
cdn缓存
将一些完全静态的数据缓存到cdn;针对一些高流量接口,可以进行静态、动态数据分离,把静态数据缓存到cdn,动态数据通过另一个接口获取。
-
内存数据库缓存
如常用的redis、memcache等,是mysql此类db不能满足性能需求下的产物。应该避免直接查询db,充分利用内存数据库。
-
内存缓存
有些接口对性能要求极高,可以将此类接口的静态数据缓存到内存,例如首屏或者首页数据;一些常用但不常变动的配置性数据也可以缓存到内存。
进行内存缓存需要关注服务的内存占用,关注增加的额外gc压力,甚至是OOM。
2. mysql
-
索引优化
创建合理的索引,关注sql的执行计划。
一般禁止全表扫描。
合理利用索引覆盖、索引下推等特性,尽量避免回表。
有排序需要,尽可能利用索引的有序性,避免file sort。
关注分页,offset越大,性能越差。
联表查询,小表驱动大表,连接字段要有索引。
-
分库分表
水平分表一般在单表记录数超大时使用,可以大大较少单表的记录数,达到降低索引B+树高度,减少查询扫描区间的io次数。
垂直分表一般在单条记录占用空间很大时使用,可以减小单表单条记录大小,从而增加聚簇索引页容纳的记录数量,一方面减少了聚簇索引使用的页数量,另一方面也降低了聚簇索引B+树高度,都可以减少查询io次数。
分库,利用硬件性能的扩展提升数据库性能。
-
合并更新
针对频繁更新的字段,进行合并更新
例如动态的浏览数字段,可以将浏览行为放到队列中,对于相同动态的浏览数变化,合并成一条sql语句进行更新
3. redis
-
避免大key、大value
使用cluster模式的redis时,可以将数据量很大的key拆分到多个实例(例如通过hash),避免出现热点实例;热点key也可以拆分到多个实例,分散压力。
-
关注单个命令耗时
由于redis单线程模型,单个命令执行时间过长会导致其他命令被阻塞,严重拖慢整个应用的运行。例如批量zadd,hmset等命令不宜一次性添加过多数据;删除一个大key时,可以使用unlink代替del(unlink会异步在另一个线程中执行删除)
-
使用cluster模式
由于redis单线程模型,单实例模式下提高机器cpu数量不能带来性能提升。使用cluster模式也更容易扩容。
4. 业务逻辑
-
使用缓存
前面已经介绍过缓存,在性能要求高且一致性要求不严格的业务逻辑中尽可能使用缓存
-
精简接口
合理设计接口,避免大量数据一个接口返回,需要客户端分模块渲染展示。
接口分版本,防止新老版本使用同一个接口,不需要的数据越来越多。
-
异步处理
将逻辑较重且没必要同步处理的逻辑改为异步处理,减小接口rt
可通过启动goroutine来处理,若对数据一致性要求较高,可使用mq
-
并发处理
查询接口中若有较多的io类方法调用,可将无依赖关系的io类方法进行并发调用,降低接口rt
启动多个goroutine与其他语言多线程一样,也同样有线程安全问题,尤其是在闭包引用外部变量时,很容易多个goroutine共享相同的变量,出现线程安全问题。(如果对共享变量没有写操作,不会有问题,但是如果调用链比较长,很难确定下层是否有写操作)
可通过传参避免多goroutine通过闭包共享变量;如果共享变量是slice或者map,即使传参,它们底层数据也是共享的,进行写操作同样有线程安全问题,可通过深度拷贝,复制变量给不同的goroutine使用。
-
批量请求
将单次查询接口改造为批量查询接口。降低网络rtt带来的延迟。
例如将循环调用单个查询用户信息接口改为一次调用批量查询用户信息接口。
-
动态、静态数据分离
动、静态数据分离是为了更容易对静态数据进行缓存
例如,将动态列表中当前登陆用户的互动数据(是否点赞、是否关注等)与动态本身数据进行分离
-
优化算法
-
熔断、降级
5. 扩容升配
扩容升配是应对突发流量的临时有效解决方案
扩容升配需要针对当前性能瓶颈才能到达更高的性价比
四、架构优化
1. 分布式
分布式的系统架构本身就是为了达到高可用、高性能的目的。
尽量避免单点服务的存在。
2. 微服务
从单体服务中将相对独立的业务模块拆分到若干微服务,一方面降低了某个业务模块故障对服务整体的影响;另一方面微服务拆分过程也是资源拆分、细化的过程,可以使得资源的分配更优。
3. 容器化
五、底层优化
1. 网络
- 连接复用
尽量使用长连接来进行通信,如grpc。http协议也可以通过设置keepalive达到连接复用的效果,可以避免频繁创建连接带来的性能消耗
- 编解码
网络协议必然涉及数据编解码,编解码算法对服务整体性能的影响很大。例如web服务中常用的json编解码,go1.13之前一般使用jsoniter包代替标准包,go1.13已经对标准包进行了优化。
- 数据压缩
可以通过压缩减小数据体积,减少传输时间
- IO多路复用
使用系统提供的IO多路复用方法,如epoll,作为网络底层,提高网络io操作效率。
在特定的场景需要自己实现网络底层来达到更优的性能。例如网关,单个服务一般要承载10w+的长连接,如果使用go原有的网络库,每个连接创建一个goroutine来处理io,大量的goroutine将成为系统瓶颈。
2. 内存
- 预分配
预分配内存可以减少频繁内存分配带来的性能消耗。例如在append slice之前,预先将slice make到一个指定大小。
- 池化、复用
对于频繁创建、销毁的内存对象,可以建立对象池进行对象复用。例如http中的Request对象,或者网络底层用于读取数据和拆分、拼接数据包的byte数组。
- 堆、栈
了解go内存逃逸分析,有助于区分堆内存和栈内存,减少堆内存的分配可以降低内存分配带来的消耗,也可以降低gc压力。
3. 锁
锁粒度拆分尽量小,避免锁定一个超长执行时间的逻辑。
可以使用原子操作(atomic包)代替锁的,尽量使用原子操作。
Author 刘玮
LastMod 2022-02-12