记一次goroutine被hang的排查经历

Contents
介绍
首先介绍下标题中的两个名词:panic和hang
Go语言中的panic可以类比与其他语言的Exception(异常),上一篇文章Panic的一生详细讲解了Go语言中的panic、recover,不再多说。
而hang的中文意思是悬挂。如果说一个进程被hang了,字面意思即进程被挂起,是指进程状态由于某些原因从运行或者就绪变为了阻塞状态,导致进程得不到执行。
遇到的问题
在开开心心地开发完一个功能后,进行接口自测,发现接口一直不返回。由于是在本地起服务自测,首先确认了没有设置断点。重复尝试了多次现象依旧。重启了服务也是一样(至于重启电脑、拔网线这种网管技能万不得已也可以试试)。
调用了一下其他接口,能够正常返回。说明问题是出在新增功能。难道新增功能里面出现了死循环?随即确认了CPU的使用率不高,应该不是死循环。为了验证,使用Go的PProf工具抓取了CPU使用统计, go tool pprof -http=:8899 http://ip:port/debug/pprof/profile?seconds=30,没有发现CPU使用过高的代码。
如果是生产环境,一般发现问题就立即回滚,恢复服务能力后再继续排查。这里由于是测试环境,我们可以随意发挥想象力。
这种接口不响应,又没有返回500、502状态码,就是进程hang的显著表现。进程被hang,在多线程程序中实际是线程被阻塞,在Go语言中则是goroutine被阻塞。线程被阻塞有可能是资源争用,例如锁竞争,也有可能是进行了会阻塞的系统调用。
试想互斥锁加锁后没有解锁,所有执行到此临界区代码的线程或goroutine都会由于获取不到锁被阻塞。这与我们遇到的情况是不是很相似?Go Http Server会为每个请求启动一个goroutine进行请求处理。其他接口没有问题,新增的接口无响应,说明新接口的goroutine都被阻塞了。
当然以上分析都是“事后诸葛亮”,我正常的排查过程是先排除了死循环,然后看日志,发现日志中有panic记录,根据panic日志定位到可疑的代码如下:
|
|
这是一个定时更新配置的方法,当配置过期后,去数据库加载并保存到内存。
为了防止配置过期后多个goroutine并发进行配置更新,使用了golang.org/x/sync/singleflight包。
singleflight的Do方法签名如下:
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool)
它可以保证相同key的多个goroutine只有一个执行fn方法,其他goroutine等待。当执行fn方法返回后,其他等待的goroutine也会收到相同的返回值。
而panic是在loadHotTalkInsertConfig方法中发生的,且loadHotTalkInsertConfig中没有recover,导致panic之后的代码逻辑被跳过,直到进入到http的Recover中间件,打印panic日志并返回错误。
我们看一下singleflight的实现:
|
|
singleflight使用sync.WaitGroup进行goroutinue间的同步,其他goroutine使用Wait方法等待信号,执行fn方法的goroutine执行完之后使用Done方法唤醒其他goroutine。
fn即我们代码中的loadHotTalkInsertConfig,它panic之后,导致Done方法没有被执行到。等待信号的goroutine会一直等待,而且后续执行到此处的goroutine同样会被阻塞在Wait调用上。
真相大白
真相大白,可以说是loadHotTalkInsertConfig中panic的锅,但是singleflight也脱不了干系。singleflight中有互斥锁也有信号量,不应该完全信任传入的方法,一旦发生意外,导致互斥锁或者信号量的方法没有成对执行,非常容易出现死锁或者永久hang。
当然遇到这个问题,我们不是独一份。已经有人在github上提了issues,开发团队也进行了优化。优化方式也比较简单,在doCall中进行defer,保证即使发生了panic,Done也能够被执行到。
然后呢
这次我们比较幸运,问题发生在测试环境,通过panic信息能够快速定位到嫌疑代码段,而且singleflight实现也简单,最终通过阅读代码找到问题所在。
如果生产环境发生了此类问题。我可以保留一台问题服务(必要时将这台保留服务从网关中摘掉),其他服务立即回滚。使用Go的PProf工具将问题服务的运行现场的统计信息抓取下来。
下图是我在测试环境重现如上问题后,抓取下来的goroutine统计信息。我进行了9次问题接口调用,9个goroutine都阻塞在Wait方法上,且这9个goroutine都来自(pos *HotTalkInsertPosConfig) Get。
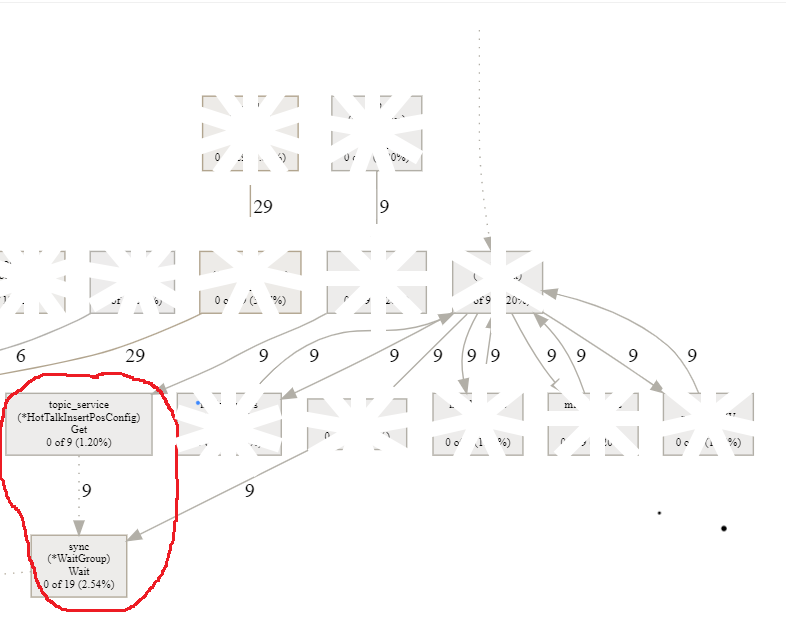
如果是生产环境,有大量的接口调用,goroutine被阻塞在哪里,在图中会非常明显。
另外,在写多线程代码时,需要对多线程安全问题特别关注。尤其是在Go中的goroutine轻量到随手可以启动一个,不要轻易假设自己的数据只会被一个goroutine读写,在使用锁和信号量时更要格外小心:
sync.Mutex的Lock和UnLock必须成对出现,建议在Lock之后立即defer Unlock。保证解锁能够被执行 sync.WaitGroup的Add和Done必须成对出现,建议在Add之后立即defer Done。保证Done能够被执行
Author 刘玮
LastMod 2022-02-12